
Search TrailBlazer is a project that aims at redefining the way people think about search. We propose to model user search behaivor using tasks rather than queries or sessions in the traditional way. Our framework contains components to impact multiple core areas of search engines, including relevance ranking, metric design, user satisfaction prediction, DSAT mining, competitive analysis and etc.
Introduction
Search engines are traditionally evaluated in terms of the relevance of web pages to individual queries. However, that does not tell the complete picture, since an individual query may represent only a piece of the user's information need. On the other hand, search engines often group queries into sessions by using simple heuristic-based time cutoff. However, we discovered in search logs that this grouping is sometimes premature since
- Often times users tend to perform multiple tasks within a single session. These tasks are sometimes even performed in an interleaved fashion (e.g., a user may open two browser tabs, with one viewing news and the other tab searching for medical information). [1]
- Many actual search tasks expand multiple sessions, or even days and weeks. For example, planning vacations. A task could contain several subtasks that occur either sequentially or at the same time. [2]
Our work tries to address this fundamental issue in search engine logs. With a better-defined granularity which we call search tasks to capture users’ information needs, our work has shown impacts on multiple search engine components.
People
| Project Lead |
|
| Contributors |
Li-wei He Ahmed Hassan Ryen White Hongning Wang Zhen Liao |
")





Projects
| Name | Description |
With-in Session Task Extraction |
We introduce task trail as a new concept to understand user search behaviors. We define task to be an atomic user information need. We propose a logistic regression-based method to group queries into task clusters efficiently. Through extensive analyses and comparisons, we discovered the effectiveness of task trails in three search applications: determining user satisfaction, predicting user search interests, and query suggestion. Supporting Materials: Publication: [1]
|
Long-term User Task Extraction
|
Most prior research on task identification has focused on short-term search tasks within a single search session, and heavily depends on human annotations for supervised classification model learning. In this work, we target the identification of long-term, or cross-session, search tasks (transcending session boundaries) by investigating inter-query dependencies learned from users' searching behavior. A semi-supervised clustering model is proposed based on the latent structural SVM framework and a set of effective automatic annotation rules are proposed as weak supervision to release the burden of manual annotation. Our learned model enables a more comprehensive understanding of search behavior via search logs and facilitates the development of dedicated search-engine support for long-term tasks. Supporting Materials: Publication: [2]
|
Search Relevance Improvement
|
We performed a large scale user study where we collected explicit judgments of user satisfaction with the entire search task. Results were analyzed using sequence models that incorporate user behavior to predict whether the user ended up being satisfied with a search or not. We test our metric on millions of queries collected from real Web search traffic and show empirically that user behavior models trained using explicit judgments of user satisfaction outperform several other search quality metrics. We propose a method that uses task level success prediction to provide a better interpretation of clickthrough data. We use our user satisfaction model to distinguish between clicks that lead to satisfaction and clicks that do not. We show that adding new features derived from this metric allowed us to improve the estimation of document relevance. Supporting Materials: Publication: [3]
|
Query Suggestion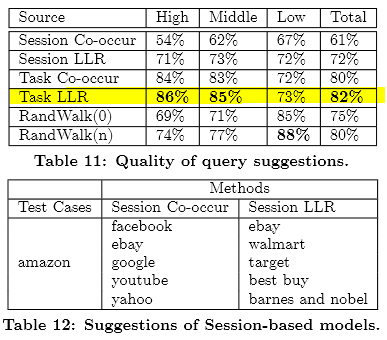 |
We compare query suggestion results to show difference among tasks, sessions, and click through bipartite graph. We build our task-based query suggestion model using different approaches including query co-occurrence, conditional likelihood ratio and random walk. We found that task-based query suggestion usually has higher quality than queries-based and session-based models, and can provide complementary results to other models. Supporting Materials: |
User Behavior Analysis 1: Task Switching
|
Engine switch has been a very important metric to assess search engines’ quality. Our previous study showed a strong correlation between the NDCG score and engine switch.
|
User Behavior Analysis 2: User Satisfaction |
Understanding the behavior of satisfied and unsatisfied Web search users is very important for improving users search experience. We use a Markov chain model to predict user search success and failure. We keep track of Bing's performance mined from user browser logs. Supporting Materials: Publication [3]
|
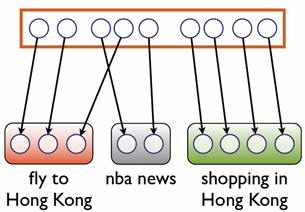


And please stay tuned, we will release more exciting projects soon!
Code for Scientific Use
Logistic regression and clustering tools to extract with-in session tasks
Structured learning code to extract cross session tasks
Web service to get query similarity and group queries into tasks
Publications
- Zhen Liao, Yang Song, Li-wei He, and Yalou Huang, Evaluating the Effectiveness of Search Task Trails, in WWW 2012, ACM, April 2012
- Hongning Wang, Yang Song, Ming-Wei Chang, Xiaodong He, Ryen White, and Wei Chu, Learning to Extract Cross-Session Search Tasks, in WWW 2013, ACM, 13 May 2013
- Ahmed Hassan, Yang Song, and Li-wei He, A Task Level User Satisfaction Metric and its Application on Improving Relevance Estimation, in ACM Conference on Information and Knowledge Management (CIKM), Association for Computing Machinery, Inc., 1 October 2011
- Ryen White, Wei Chu, Ahmed Hassan, Xiaodong He, Yang Song, and Hongning Wang, Enhancing Personalized Search by Mining and Modeling Task Behavior, in WWW 2013, ACM, 13 May 2013
- Zhen Liao, Yang Song, Yalou Huang, Li-wei He, and Qi He, Task Trail: An Effective Segmentation of User Search Behavior, in ACM Transactions on Knowledge and Data Engineering (TKDE), ACM, 2014
Questions and Comments?
Please contact ys at sonyis dot me for questions.